






 요약
요약
Generating preferred images using generative adversarial networks (GANs) is challenging owing to the high-dimensional nature of latent space. In this study, we propose a novel approach that uses simple user-swipe interactions to generate preferred images for users. To efectively explore the latent space with only swipe interactions, we apply principal component analysis to the latent space of the StyleGAN, creating meaningful subspaces. We use a multi-armed bandit algorithm to decide the dimensions to explore, focusing on the preferences of the user. Experiments show that our method is more eficient in generating preferred images than the baseline methods. Furthermore, changes in preferred images during image generation or the display of entirely diferent image styles were observed to provide new inspirations, subsequently altering user preferences. This highlights the dynamic nature of user preferences, which our proposed approach recognizes and enhances.
적절한 이미지를 생성하기 위해 생성적 적대 신경망(GANs)을 사용하는 것은 잠재 공간의 고차원적인 특성 때문에 어려운 과제입니다. 본 연구에서는 사용자가 선호하는 이미지를 생성하기 위해 간단한 사용자 스와이프 상호작용을 활용하는 혁신적인 접근 방법을 제안합니다. 스와이프 상호작용만으로 잠재 공간을 효과적으로 탐색하기 위해 StyleGAN의 잠재 공간에 주성분 분석을 적용하여 의미 있는 부공간을 만듭니다. 사용자의 선호도에 초점을 맞추기 위해 MAB 알고리즘을 사용하여 탐색할 차원을 결정합니다. 실험 결과, 우리의 방법이 기준 선방법들보다 선호하는 이미지를 생성하는 데 더 효율적임을 보여줍니다. 또한, 이미지 생성 중에 선호하는 이미지의 변화나 완전히 다른 이미지 스타일의 표시가 새로운 영감을 제공하고, 이에 따라 사용자 선호도가 변화하는 것을 관찰했습니다. 이는 우리가 제안한 방법이 사용자 선호도의 동적인 특성을 인식하고 강화한다는 점을 강조합니다.
소개
Generative adversarial networks (GANs) facilitate the generation of high-quality images. One of the notable features of GANs is their ability to allow users to modify these images by adjusting latent variables [12]. It is essential to select the correct latent variables to obtain the desired results; however, choosing the right latent variables is challenging given the high dimensionality of the latent space of GANs. Previous research suggested using multiple sliders [5, 12, 31, 32] or image editing tools [40] to allow users to modify the images. These approaches are sometimes inconvenient for users to apply, especially on smartphones, where the limited screen space complicates the use of sliders and editing tools. Although text-to-image techniques ofer a potential solution to generate preferred images, users often find it challenging to design appropriate prompts.
적대적 생성 신경망(GANs)은 고품질 이미지를 생성하는 것을 용이하게 합니다. GANs의 주목할만한 기능 중 하나는 잠재 변수를 조절하여 이러한 이미지를 수정할 수 있는 능력입니다. 원하는 결과를 얻기 위해 올바른 잠재 변수를 선택하는 것은 중요합니다. 그러나 GANs의 잠재 공간의 고차원성 때문에 올바른 잠재 변수를 선택하는 것은 어렵습니다. 이전 연구에서는 사용자가 이미지를 수정할 수 있도록 여러 슬라이더 또는 이미지 편집 도구를 사용하는 것을 제안했습니다. 이러한 방법은 때로는 사용자가 적용하기 불편할 수 있으며, 스마트폰에서는 화면 공간이 제한되어 있어 슬라이더나 편집 도구의 사용이 복잡해집니다. 사용자가 선호하는 이미지를 생성하기 위한 해결책으로 텍스트-이미지 기술이 제시되었지만, 사용자는 적절한 프롬프트를 설계하는 것이 어려워합니다.
In this study, we propose a method that allows users to generate images based on their preferences with minimal interaction. Our system uses swipe actions, commonly used in smartphone inter-faces. An overview of our approach is illustrated in Figure 1. Given the familiarity many users have with swipe-based applications such as Tinder1, we design our user interface to present one image at a time, relying on swipe gestures for feedback. Instead of exten-sive user input, our system estimates preferences based on these swipes. When the system displays an image, users swipe to indicate their preference. Based on this feedback, the system generates new images that better match these preferences. With repeated interac-tions, the system becomes more adept at producing images aligned with what the user likes and dislikes.
이 연구에서는 사용자들이 최소한의 상호작용으로 선호에 기반한 이미지를 생성할 수 있는 방법을 제안합니다. 저희 시스템은 스마트폰 인터페이스에서 흔히 사용되는 스와이프 동작을 활용합니다. 우리의 접근 방식에 대한 개요는 도식화된 그림 1에 나와 있습니다. Tinder와 같은 스와이프 기반 애플리케이션에 익숙한 많은 사용자들을 고려하여, 우리는 한 번에 한 장의 이미지를 보여주는 사용자 인터페이스를 설계했습니다. 이 사용자 인터페이스는 피드백을 위해 스와이프 동작을 의존합니다. 방대한 사용자 입력 대신, 시스템은 이러한 스와이프를 기반으로 선호도를 추정합니다. 시스템이 이미지를 표시하면 사용자는 선호도를 나타내기 위해 스와이프합니다. 이 피드백을 기반으로 시스템은 이러한 선호에 더 잘 부합하는 새로운 이미지를 생성합니다. 반복된 상호작용을 통해 시스템은 사용자가 좋아하고 싫어하는 것과 일치하는 이미지를 더 잘 생성할 수 있게 됩니다.
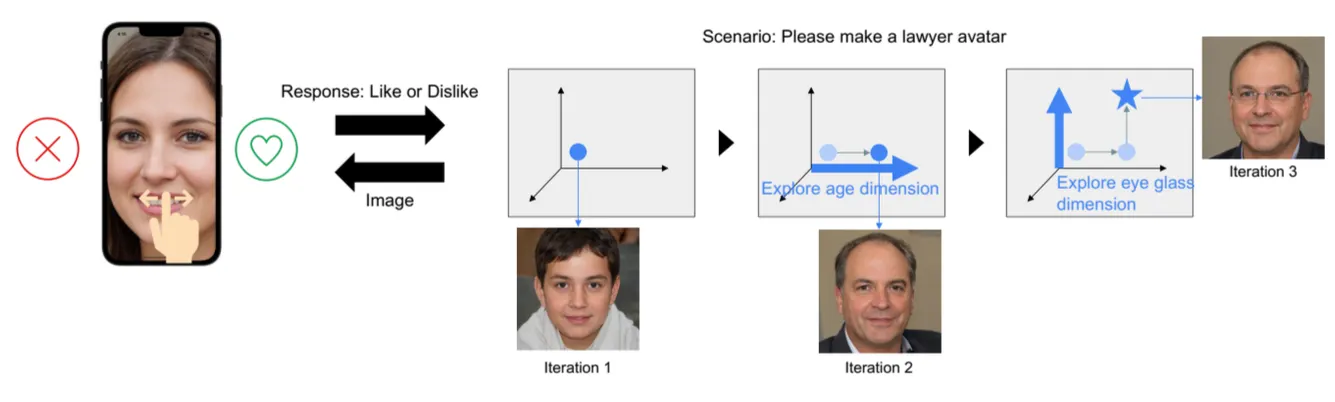
그림 1: 스와이프를 통한 이미지 생성 개요. 이 예시는 사용자 스와이프에 기반하여 시스템이 어떻게 변호사 아바타를 생성하는지를 보여줍니다. 연속적인 스와이프 피드백을 해석함으로써, 시스템은 사용자 선호에 맞춰 표시된 이미지를 동적으로 조정합니다. 내부적으로는 나이 또는 안경 착용 여부와 같은 차원을 평가합니다. 예를 들어, 2번째 반복(iteration)에서는 시스템이 추정된 사용자 선호에 따라 아바타의 나이를 업데이트합니다. 세 번째 반복에서는 피드백에 따라 아바타에 안경이 추가됩니다.
To evaluate the eficiency of our proposed method in generating user-preferred images, we performed both simulation and user experiments. The simulation results indicate that, in cases of large subspace dimensionality, our method is more eficient than the baseline method. The result of user experiments also show that our method can generate preferred images more eficient than the baseline method. Moreover, we observed that user preferences can shift when comparing images. Our proposed method efectively accommodated these changes, promoting a broader scope for user exploration.
우리가 제안한 방법이 사용자 선호 이미지를 생성하는 데 효율적인지를 평가하기 위해 시뮬레이션 및 사용자 실험을 수행했습니다. 시뮬레이션 결과에 따르면 대규모 부분공간 차원의 경우, 우리의 방법이 기준 방법보다 더 효율적임을 나타냅니다. 사용자 실험 결과도 우리의 방법이 기준 방법보다 더 효율적으로 선호 이미지를 생성할 수 있다는 것을 보여줍니다. 또한, 이미지를 비교할 때 사용자 선호도가 변할 수 있다는 것을 관찰했습니다. 우리의 제안된 방법은 이러한 변경 사항을 효과적으로 수용하여 사용자의 탐색 범위를 확대시켰습니다.
Our contributions are summarized as follows:
• We introduce a novel user interface for generating userpreferred images that are simply controlled with a swipe. Users can easily generate these images by repeatedly swiping, similar to how they would use a matchmaking app.
• To eficiently explore the GAN latent space using minimal feedback from swipe interactions, we devise an approach that integrates Bayesian optimization with a multi-armed bandit algorithm. This algorithm dynamically determines the dimensions within the subspace that are of interest to the user.
• Through the user study, we confirmed the eficiency of our proposed method in generating preferred images. Furthermore, we observed a gradual shift in user preferences when presented with pairwise comparisons. Our method not only accommodates shifts in user preferences but also allows users to reconsider and adjust their choices.
우리의 기여는 다음과 같습니다:
•
스와이프를 사용하여 간단하게 제어되는 사용자 선호 이미지를 생성하기 위한 새로운 사용자 인터페이스를 소개합니다. 사용자는 일치 앱을 사용하는 방식과 유사하게 반복해서 스와이프하여 이러한 이미지를 쉽게 생성할 수 있습니다.
•
사용자 피드백을 최소한으로 활용하여 GAN 잠재 공간을 효율적으로 탐색하기 위해 베이지안 최적화와 멀티암드밴딧 알고리즘을 통합하는 접근 방법을 개발했습니다. 이 알고리즘은 동적으로 사용자에게 관심이 있는 하위 공간 내의 차원을 결정합니다.
•
사용자 연구를 통해 우리의 제안 방법이 선호 이미지를 생성하는 데 효율적임을 확인했습니다. 또한, 사용자가 이진 비교를 통해 제시될 때 선호도에 점진적인 변화를 관찰했습니다. 우리의 방법은 사용자 선호도의 변화를 수용하는 데 뿐만 아니라 사용자가 선택을 재고하고 조정할 수 있도록 합니다.
선행 연구
2.1 GANs에서 선호 이미지 생성하기
Recently, there has been a surge in interest in image-generation models such as variational autoencoders [17], GANs [9, 15, 37, 41],autoregressive models [10, 23, 34, 36], and difusion models [13, 25,27, 28]. In particular, GANs can produce high-quality images, which has led to an increased focus on image-generation methods tailored for user preferences. One approach to generating preference images is to use conditional GANs [11, 14, 24, 38, 41]. However, these approaches required custom network architectures and training data to control particular applications. Unlike previous studies, our approach uses a pre-trained model and does not require further training.
최근, 가변 오토인코더 [17], GANs [9, 15, 37, 41], 자회귀 모델 [10, 23, 34, 36], 및 확산 모델 [13, 25, 27, 28]과 같은 이미지 생성 모델에 대한 관심이 급증했습니다. 특히, GANs는 고품질 이미지를 생성할 수 있어 사용자 선호도에 맞는 이미지 생성 방법에 대한 관심이 높아졌습니다. 선호 이미지를 생성하는 한 가지 방법은 조건부 GANs [11, 14, 24, 38, 41]를 사용하는 것입니다. 그러나, 이러한 방법들은 특정 응용 프로그램을 제어하기 위해 사용자 정의 네트워크 아키텍처와 학습 데이터가 필요했습니다. 이전 연구들과는 달리, 우리의 방법은 사전에 학습된 모델을 사용하며 추가로 학습을 요구하지 않습니다.
Research on image-generation control has been conducted by analyzing the latent space of pre-trained deep generative models. By controlling the latent space, preference images can be generated by drawing or coloring on a blank canvas [2, 40], adjusting multiple sliders [12, 31, 32, 35]. In contrast to previous studies, our approach focuses on simplifying user input by introducing swiping, the simplest method of interaction. Previous studies have controlled attributes in the latent space by providing users with canvas, sliders, and so on, and required them to draw sketches or adjust multiple sliders, which can be dificult for users. In contrast, our method can generate preferred images using only swiping actions. Furthermore, our method is especially beneficial in cases where users do not have or are unable to express their preferences clearly. Existing studies assume that users have a clear idea of what they want. However, our method does not make this assumption, allowing them to generate any image they prefer even when they cannot express their intentions accurately. Without a clear object, a preferred image can be created by simply selecting the preferred image.
이미지 생성 제어에 대한 연구는 사전에 학습된 딥 생성 모델의 잠재 공간을 분석함으로써 수행되었습니다. 잠재 공간을 제어함으로써, 선호 이미지를 생성할 수 있습니다. 이전 연구들과 달리, 우리의 방법은 사용자 입력을 간소화하기 위해 스와이핑이라는 가장 간단한 상호작용 방법을 도입합니다. 이전 연구들은 사용자에게 캔버스, 슬라이더 등을 제공하여 스케치를 그리거나 여러 슬라이더를 조절하도록 하여 잠재 공간 내의 속성을 제어했지만, 이는 사용자에게 어려울 수 있습니다. 반면, 우리의 방법은 스와이핑 동작만으로도 선호 이미지를 생성할 수 있습니다. 또한, 사용자가 자신의 선호도를 명확하게 표현하지 못 할 때 특히 유용합니다. 기존 연구들은 사용자가 무엇을 원하는지 명확히 이해하고 있다고 가정합니다. 그러나, 우리의 방법은 이러한 가정을 하지 않고, 사용자가 의도를 정확하게 표현할 수 없는 경우에도 원하는 이미지를 생성할 수 있도록 허용합니다. 명확한 대상이 없는 경우에도 원하는 이미지를 선택함으로써 선호 이미지를 만들 수 있습니다.
2.2 휴먼 인 더 루프(Human-in-the-loop) 최적화
To generate preferred images using only swiping actions, it is necessary to search efectively in the latent space. Therefore, we used human-in-the-loop optimization, which is an eficient way to explore parameters when editing images. Human-in-the-loop optimization involves humans as computational resources in it-erative optimization computations. It is advantageous to include humans in iterations, especially when optimizing for human prefer-ences. Owing to these advantages, it has been widely used in recent years [5, 7, 16, 19, 20, 30, 39]. Bayesian optimization for human-in-the-loop is a collaborative problem-solving approach between humans and computers. The computer samples potential solutions to optimize the objective function and requests humans to evaluate those candidates. This process is repeated until a desirable solutionis found. In this approach, it is particularly important to ask questions that humans can easily answer and to reduce the number of queries.
휴먼 인 더 루프 최적화를 사용하여 선호 이미지를 생성하기 위해 잠재 공간에서 효과적으로 검색해야 합니다. 따라서 우리는 휴먼 인 더 루프 최적화를 사용했습니다. 휴먼 인 더 루프 최적화는 인간을 계산 자원으로 사용하여 반복적 최적화 계산에서 파라미터를 탐색하는 효율적인 방법입니다. 특히 인간 선호도를 최적화할 때 인간을 반복에 포함하는 것이 유리합니다. 이러한 이점으로 인해 휴먼 인 더 루프 최적화는 최근 많이 사용되어 왔습니다. 휴먼 인 더 루프에 대한 베이지안 최적화는 인간과 컴퓨터 간의 협력적 문제 해결 방식입니다. 컴퓨터는 목적 함수를 최적화하기 위해 잠재 솔루션을 샘플링하고 그 후보들을 인간에게 평가하도록 요청합니다. 이 과정은 원하는 솔루션이 찾아질 때까지 반복됩니다. 이 접근 방식에서는 인간이 쉽게 답변할 수 있는 질문을 하고 질문의 수를 줄이는 것이 특히 중요합니다.
It is dificult to obtain consistent absolute evaluations for a single design. Therefore, using relative evaluations on multiple candidates is recommended [3, 33]. Brochu et al. [4] proposed preferential Bayesian optimization [8], which uses Bayesian optimization with preference comparison data, and various extensions have been made since then [5, 19, 20]. For typical parameter spaces (around 10 dimensions), interfaces such as slider adjustments [20] and Npair comparisons [19] have been proposed. However, these studies have shown that these sequential line search methods are not efective because the latent space of GANs is high-dimensional (512-dimensions). Moreover, they require users to respond to more complicated queries such as multiple slider adjustments and image editing, which are cognitively burdensome. Our study proposes generating preference images using only swipe operations, even in a high-dimensional search space. We present two steps to generate images using only swipe operations. First, we apply PCA to StyleGAN latent space and created a subspace composed of directions that significantly alter the appearance of images, thus reducing the exploration range. Second, we use a multi-armed bandit algorithm to determine the exploration dimension, allowing focused exploration in dimensions of interest to the user.
한 디자인에 대해 일관된 절대 평가를 얻는 것은 어렵습니다. 따라서 여러 후보들에 대한 상대적 평가를 사용하는 것이 권장됩니다. Brochu 등 [4]은 선호도 비교 데이터를 사용하는 베이지안 최적화를 제안했고, 이후 다양한 확장이 이루어졌습니다. 전형적인 매개 변수 공간 (약 10차원)에 대해 슬라이더 조정 및 N 쌍 비교와 같은 인터페이스가 제안되었습니다. 그러나 이러한 순차적 선 검색 방법이 효과적이지 않음을 보여준 연구가 있습니다. 또한 생성적 적대 신경망의 잠재 공간은 고차원(512차원)이기 때문에 사용자에게 다중 슬라이더 조정 및 이미지 편집과 같이 더 복잡한 질문에 답변해야 합니다. 우리의 연구는 고차원 검색 공간에서도 휴먼 인 더 루프만을 사용하여 선호 이미지를 생성하도록 제안합니다.
이미지 생성 비교 스와이프
3.1. 이미지 생성을 위한 스와이프 인터랙션
We introduce a new user interface, illustrated in Figure 1, designed to generate user-preferred images using simple swipe actions. This interface captures user preferences by continuously processing swipe interactions to generate the preferred images. Inspired by smartphone matchmaking applications such as Tinder, our interface displays a single image at a time. Users are asked to perform pairwise comparisons by comparing the currently displayed image with the previous one: swiping right indicates a preference for the current image, whereas swiping left favors the earlier one. Depending on this feedback, subsequent images are generated and presented. This process continues until the image aligns with the preference of the user.
우리는 사용자 선호에 맞는 이미지를 생성하기 위해 간단한 스와이프 동작을 사용하는 새로운 사용자 인터페이스를 소개합니다. 이 인터페이스는 사용자 선호를 지속적으로 처리하는 스와이프 상호작용을 통해 선호하는 이미지를 생성합니다. Tinder와 같은 스마트폰 매칭 애플리케이션에서 영감을 받아, 우리 인터페이스는 한 번에 하나의 이미지를 표시합니다. 사용자에게는 현재 표시된 이미지를 이전 이미지와 비교하도록 요청되며, 오른쪽으로 스와이프하면 현재 이미지에 대한 선호를 나타내고, 왼쪽으로 스와이프하면 이전 이미지를 선호하는 것으로 간주됩니다. 이 피드백에 따라 다음 이미지가 생성되어 제시됩니다. 이 과정은 사용자의 선호와 일치하는 이미지가 생성될 때까지 계속됩니다.
3.2. 효율적인 잠재 공간 탐색을 위해 제안된 방법
3.2.1. 이미지 생성 모델
We use StyleGAN [15] to generate high-quality images and to support latent-space encoding style information. We sample a random vector 𝒛 from the latent space of StyleGAN and use it as the input to the mapping network to obtain the intermediate latent variable 𝒘, which contains the information about the style. The synthesis network then takes 𝒘 as the input to generate images, allowing control over the style of the generated images.
우리는 StyleGAN [15]을 사용하여 고품질 이미지를 생성하고 잠재 공간 인코딩 스타일 정보를 지원합니다. 우리는 StyleGAN의 잠재 공간에서 랜덤 벡터 𝒛를 샘플링하고, 이를 매핑 네트워크의 입력으로 사용하여 스타일 정보를 포함하는 중간 잠재 변수 𝒘를 얻습니다. 이후 합성 네트워크는 𝒘를 입력으로 받아 이미지를 생성하며, 생성된 이미지의 스타일을 조절할 수 있게 해줍니다.
3.2.2. 목표 함수
To generate preference images, it is necessary to search for optimal latent variables. We consider an optimization problem that takes human preferences as an objective function and intermediate latent variables 𝒘 ∈ 𝑊 in StyleGAN as search variables. Let the synthesis network of StyleGAN be 𝑠 : 𝑊 → 𝑋,
where 𝑊 ⊂ R𝑑is a high-dimensional space such as 𝑑 = 512, and𝑋 ⊂ Rℎ×𝑤 is an image data space such that ℎ = 𝑤 = 1,024. A user attempts to generate image data 𝒙 ∈ 𝑋 using this generation model, 𝑠, but only the vector 𝒘 ∈ 𝑊 can be controlled. The preference for image data 𝒙 is determined by the function 𝑔 : 𝑋 → R, which is unknown to the system. The goal is to solve the following optimization problem to generate images with high preferences:
선호 이미지 생성을 위해 최적의 잠재 변수를 검색해야 합니다. 우리는 인간의 선호를 목표 함수로 삼고, StyleGAN의 중간 잠재 변수를 검색 변수로 삼는 최적화 문제를 고려합니다. StyleGAN의 합성 네트워크를 𝑠 : 𝑊 → 𝑋로 정의하고, 여기서 𝑊 ⊂ R𝑑는 고차원 공간이며 𝑑 = 512와 같이 설정하고, 𝑋 ⊂ Rℎ×𝑤는 이미지 데이터 공간으로 ℎ = 𝑤 = 1,024입니다. 사용자는 이 생성 모델 𝑠를 사용하여 이미지 데이터 𝒙 ∈ 𝑋를 생성하려고 하지만, 오직 벡터 𝒘 ∈ 𝑊만 제어할 수 있습니다. 이미지 데이터 𝒙에 대한 선호는 함수 𝑔 : 𝑋 → R에 의해 결정되며, 이는 시스템에 알려져 있지 않습니다. 따라서 높은 선호를 가진 이미지를 생성하기 위해 다음의 최적화 문제를 풀어야 합니다:
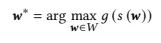
식 (1)
where 𝑔 (𝑠 (𝒘)) can be computed for any point 𝒘, but 𝑔 (·) is expensive to evaluate, and it is important to reduce the number of function evaluations as much as possible.
여기서 𝑔(𝑠(𝒘))는 어떤 점 𝒘에 대해서도 계산할 수 있지만, 𝑔(·)의 평가는 비싸므로 함수 평가의 수를 가능한 한 줄이는 것이 중요합니다.
3.2.3. 쌍별 비교 데이터에 의한 베이지안 최적화
We use Bayesian optimization [30] to evaluate the objective function and solve Equation (1). We consider Bayesian optimization by defining a composite function 𝑓 = 𝑔◦𝑠 of 𝑔 and 𝑠, where 𝑓 is the objective function. Instead of directly using the value of 𝑓 , our proposed method incorporates the pairwise comparison results provided by the user. By applying the existing method [6]2, the results of the pairwise comparisons are converted into real values based on the Bayesian estimation to compute 𝑓 . We set the hyperparameters with default values. When querying users, latent variables 𝒘 are converted to images 𝒙 ∈ 𝑋 using the synthesis network in StyleGAN.
우리는 베이지안 최적화를 사용하여 목표 함수를 평가하고 식 (1)을 해결합니다. 우리는 𝑔와 𝑠의 합성 함수 𝑓 = 𝑔◦𝑠를 정의하여 베이지안 최적화를 고려합니다. 𝑓의 값을 직접 사용하기보다는, 우리의 제안된 방법은 사용자가 제공한 쌍별 비교 결과를 포함합니다. 기존 방법 [6]을 적용하여 쌍별 비교 결과를 베이지안 추정을 기반으로 실수 값으로 변환하여 𝑓를 계산합니다. 하이퍼파라미터는 기본값으로 설정합니다. 사용자를 쿼리할 때, 잠재 변수 𝒘는 StyleGAN의 합성 네트워크를 통해 이미지 𝒙 ∈ 𝑋로 변환됩니다.
3.2.4. 차원 축소
One issue with pairwise comparisons is that the number of inquiries to humans increases due to the small amount of user preference information obtained from each iteration. Elena et al. [26] demonstrated that when performing Bayesian optimization in a high-dimensional space, the search can proceed eficiently by applying PCA to the search space, reducing the real search space. In GANSpace [12], PCA is applied to the latent space of StyleGAN to identify principal components that significantly change the appearance of images. Inspired by them, we applied PCA to the latent space of StyleGAN and explored in a subspace composed of principal components only to streamline the search for latent variables.
쌍대 비교에서 발생하는 한 가지 문제는 각 반복에서 얻는 사용자 선호 정보의 양이 적어 인간에게 문의해야 하는 횟수가 증가한다는 것입니다. Elena 등[26]은 고차원 공간에서 베이지안 최적화를 수행할 때 PCA를 적용하여 검색 공간을 줄임으로써 효율적으로 검색을 진행할 수 있음을 보여주었습니다. GANSpace[12]에서는 StyleGAN의 잠재 공간에 PCA를 적용하여 이미지의 외관을 유의미하게 변화시키는 주성분을 식별합니다. 이를 바탕으로, 우리는 StyleGAN의 잠재 공간에 PCA를 적용하여 주성분으로만 구성된 부분 공간을 탐색하여 잠재 변수를 효율적으로 검색하는 방법을 제안했습니다.
Figure 2 shows an overview of the proposed method. First, 𝑁vectors 𝒛 ∈ R𝑑are randomly sampled from the standard normal distribution. Next, by inputting the sampled 𝒛 into the StyleGAN mapping network, the intermediate latent variable 𝒘 ∈ 𝑊 ⊂ R𝑑is obtained. Using 𝒘, PCA is performed to create a 𝑑′-dimensional subspace 𝑊 ′ ⊂ R𝑑′with the top 𝑑′ principal components in terms of the contribution rate. Thereafter, Bayesian optimization is per-formed within subspace 𝑊 ′. The evaluation point proposed 𝒘′ ∈𝑊 ′in Bayesian optimization has a dimension of 𝑑′ ≠ 𝑑, which makes it impossible to directly input it into the StyleGAN synthesis network. To solve this, the inverse transformation of PCA is used to map 𝒘′ onto the latent space 𝑊 of StyleGAN, which is then inputted into the synthesis network. The generated image is then presented to the user and a pairwise comparison result with the last generated image is obtained.
그림 2는 제안된 방법의 개요를 보여줍니다. 먼저, 𝑁개의 벡터 𝒛 ∈ R𝑑가 표준 정규 분포에서 무작위로 샘플링됩니다. 다음으로, 샘플링된 𝒛를 StyleGAN 매핑 네트워크에 입력하여 중간 잠재 변수 𝒘 ∈ 𝑊 ⊂ R𝑑를 얻습니다. 𝒘를 사용하여 PCA를 수행하여 기여율에 따라 상위 𝑑′ 주성분으로 구성된 𝑑′ 차원의 부분 공간 𝑊 ′ ⊂ R𝑑′을 생성합니다. 그 후, 부분 공간 𝑊 ′ 내에서 베이지안 최적화가 수행됩니다. 베이지안 최적화에서 제안된 평가점 𝒘′ ∈ 𝑊 ′는 차원 𝑑′ ≠ 𝑑을 가지므로 직접적으로 StyleGAN 합성 네트워크에 입력할 수 없습니다. 이를 해결하기 위해 PCA의 역변환을 사용하여 𝒘′를 StyleGAN의 잠재 공간 𝑊로 매핑한 후, 이를 합성 네트워크에 입력합니다. 생성된 이미지는 사용자에게 제시되며, 이전에 생성된 이미지와의 쌍대 비교 결과를 얻습니다.
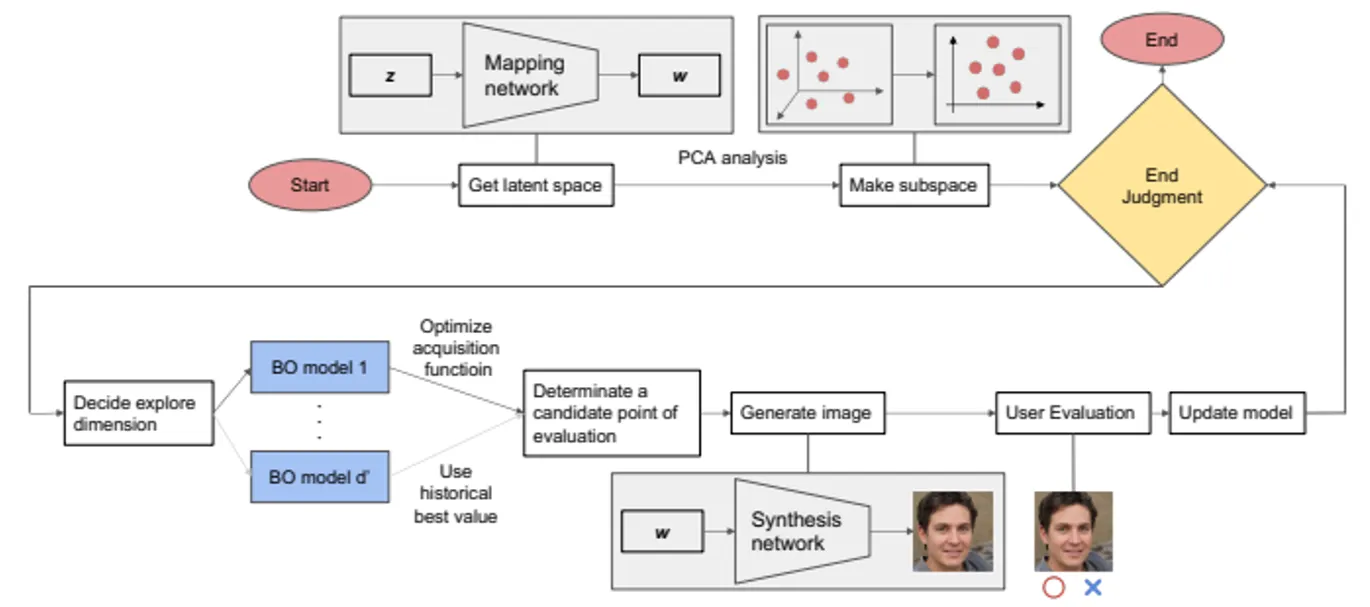
그림 2: 제안된 방법의 개요: 우리는 초기에는 PCA를 사용하여 StyleGAN의 잠재 공간으로부터 하위 공간을 도출합니다. 다음으로, 시스템은 멀티암드 밴딧 알고리즘을 사용하여 주요 차원을 식별하고 이 차원의 잠재 공간 내에서 베이지안 최적화를 수행합니다. 결과로 생성된 잠재 변수를 이미지로 변환하여 사용자에게 제시합니다. 사용자 피드백을 바탕으로 모델이 적절히 업데이트됩니다.
3.3. 주요 차원 식별
The size of the subspace should be kept large to maintain the capacity of GAN for expression. However, if the dimensionality of the subspace is increased, Bayesian optimization will not be efective in high-dimensional spaces [22], making it dificult to generate preferred images using Bayesian optimization alone. To enhance the search eficiency, we apply a multi-armed bandit algorithm to dynamically determine the dimensions for exploration. Specifically, a Bayesian optimization model is prepared for each dimension in advance, the multi-armed bandit algorithm is used to select the key dimension for the search, and candidate points are determined using the Bayesian optimization model. The candidate points are then converted into images to obtain user feedback. The multi-armed bandit model is updated using the results of image comparisons from users.
서브스페이스의 크기는 GAN의 표현 능력을 유지하기 위해 충분히 크게 유지해야 합니다. 그러나 서브스페이스의 차원 수가 증가하면, 베이지안 최적화가 고차원 공간에서 효과적이지 않게 되어, 베이지안 최적화만으로는 선호하는 이미지를 생성하는 데 어려움이 발생합니다. 탐색 효율성을 높이기 위해, 우리는 멀티암드 밴딧 알고리즘을 적용하여 탐색을 위해 동적으로 차원을 결정합니다. 구체적으로, 미리 각 차원에 대한 베이지안 최적화 모델이 준비되고, 멀티암드 밴딧 알고리즘을 사용하여 검색을 위한 주요 차원을 선택한 후, 후보 지점은 베이지안 최적화 모델을 사용하여 결정됩니다. 후보 지점은 이미지로 변환되어 사용자 피드백을 얻습니다. 이후, 멀티암드 밴딧 모델은 사용자로부터의 이미지 비교 결과를 사용하여 업데이트됩니다.
We apply the upper confidence bound (UCB) algorithm [1], a common multi-armed bandit algorithm, due to its notable performance and simplicity in implementation. The UCB algorithm calculates the UCB score for each dimension in each iteration and searches for the dimension with the highest UCB score. At the 𝑡-th iteration, assuming that the number of times that the 𝑖-th dimension is searched so far is 𝑁𝑖 and the estimated value of the reward is 𝑟ˆ𝑖, the UCB score for the 𝑖-th dimension 𝑈𝑖is calculated by
우리는 notable한 성능과 간단한 구현 때문에 일반적인 멀티암드 밴딧 알고리즘인 상한 신뢰 구간(Upper Confidence Bound, UCB) 알고리즘을 적용합니다. UCB 알고리즘은 각 반복에서 각 차원의 UCB 점수를 계산하고, 가장 높은 UCB 점수를 가진 차원을 검색합니다. 𝑡-th 반복에서, 𝑖-th 차원이 지금까지 검색된 횟수를 𝑁𝑖, 보상의 추정 값을 𝑟ˆ𝑖라고 가정할 때, 𝑖-th 차원의 UCB 점수 𝑈𝑖는 다음과 같이 계산됩니다.
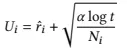
식 (2) i차원의 UCB 점수
where 𝛼 is a hyperparameter that adjusts the trade-of between exploration and exploitation.
𝑈𝑖is used to select the largest dimension 𝑖∗:
𝛼는 탐색(exploration)과 활용(exploitation) 간의 균형을 조정하는 하이퍼파라미터입니다. 𝑈𝑖는 가장 큰 차원 𝑖∗를 선택하는 데 사용됩니다.
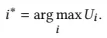
식 (3)
The multi-armed bandit model is then updated as follows:
멀티암드 밴딧 모델은 다음과 같이 업데이트됩니다.
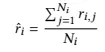
식 (4)
where 𝑟𝑖,𝑗 ∈ {0, 1} is the reward when the 𝑖-th dimension is selected for the 𝑗-th time. If the last generated image is selected, then 𝑟𝑖,𝑗 = 0, and if the current generated image is selected, then 𝑟𝑖,𝑗 = 1. For the selected dimension 𝑖∗, Bayesian optimization is used to determine the 𝑖∗components of the candidate points. Let 𝐴 be the acquisition function and 𝑤𝑖∗ be the 𝑖∗-th component of the candidate point:
주어진 식에서 𝑟𝑖,𝑗 ∈ {0, 1}은 𝑗-번째로 선택된 𝑖-번째 차원에 대한 보상을 나타냅니다. 마지막으로 생성된 이미지가 선택되면 𝑟𝑖,𝑗 = 0이고, 현재 생성된 이미지가 선택되면 𝑟𝑖,𝑗 = 1입니다. 선택된 차원 𝑖∗에 대해, 베이지안 최적화를 사용하여 후보 점의 𝑖∗-번째 구성 요소인 𝑤𝑖∗를 결정합니다. Acquisition function을 𝐴로 표현합니다.
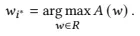
식 (5)
For dimensions other than 𝑖∗, we assign the best value of the Bayesian optimization model for each dimension based on previous observations. Let 𝑤0,𝑤1,. . . , 𝑤𝑑′ be the best values for each dimension and 𝒘′𝒕= [𝑤0,𝑤1,. . . , 𝑤𝑖∗ ,. . . , 𝑤𝑑′ ] be the candidate evaluation point at the 𝑡-th iteration. The candidate point 𝒘′𝒕is transformed into an image using the inverse transform of PCA and the synthesis network to query the user.
다른 차원에 대해서는 이전 관측값을 기반으로 베이지안 최적화 모델의 최적 값을 각 차원에 할당합니다. 𝑤0, 𝑤1, …, 𝑤𝑑′는 각 차원의 최적 값이며, 𝒘′𝒕 = [𝑤0, 𝑤1, …, 𝑤𝑖∗, …, 𝑤𝑑′]는 𝑡-번째 반복에서의 후보 평가 지점입니다. 후보 지점 𝒘′𝒕는 PCA의 역변환과 합성 네트워크를 사용하여 이미지를 변환하여 사용자에게 질의합니다.
시뮬레이션 실험
4.1. 실험 설정
To evaluate whether the proposed method eficiently approaches preferred images assuming that the user provides a stable response, we conducted a simulation experiment. We compared our method (BanditBO) with the baseline method (SimpleBO) without the bandit algorithm from the proposed method. Figure 3 shows an overview of the simulation experiment. We simulated a situation in which a user has a specific goal of creating an image using our system. To generate the pairwise comparison results, we predefined a target image, calculated the similarity between the generated and target images, and compared it with the results of previous iterations.
사용자가 안정적인 반응을 제공한다고 가정했을 때, 제안된 방법이 선호하는 이미지를 효과적으로 접근하는지를 평가하기 위해 시뮬레이션 실험을 진행했습니다. 우리는 제안된 방법에서 밴딧 알고리즘이 없는 기초 방법(SimpleBO)과 우리의 방법(BanditBO)을 비교했습니다. 그림 3은 시뮬레이션 실험의 개요를 보여줍니다. 우리는 사용자가 시스템을 사용하여 특정 이미지를 생성하려는 목표를 가지는 상황을 시뮬레이션했습니다. 쌍별 비교 결과를 생성하기 위해, 목표 이미지를 미리 정의하고 생성된 이미지와 목표 이미지 간의 유사성을 계산한 후, 이전 반복 결과와 비교했습니다.
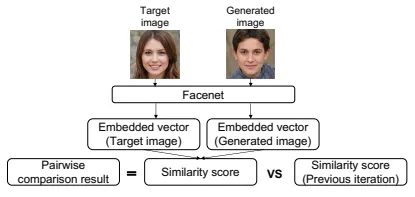
그림 3: 시뮬레이션 실험을 위한 쌍대 비교 생성. 쌍대 비교를 생성하려면 두 단계가 필요합니다. 첫째, 시스템은 대상의 임베딩 벡터를 얻고 Facenet을 사용하여 이미지를 생성합니다. 둘째, 시스템은 이러한 두 벡터의 코사인 유사성을 취하고 이 유사성을 이전 반복의 유사성과 비교하여 쌍대 비교 결과를 생성합니다.
The pairwise comparison results were then input into the Bayesian optimization system. The dimensionality of the subspace 𝑊 ′ was set to 𝑑′ ∈ {4, 8, 16}. Ten target images were randomly selected from the search space for this experiment.W e used a pre-trained StyleGAN model that was originally trained on the Flickr-FacesHQ (FFHQ) dataset [15]. The FFHQ dataset is designed as a GAN benchmark and comprises more than 70,000 images of human faces sized 1,024 × 1,024, covering various ages, gender, races, and facial expressions.
제안된 방법에서 쌍(pairwise) 비교 결과는 베이지안 최적화 시스템에 입력되었습니다. 서브스페이스 의 차원은 로 설정되었습니다. 실험을 위해 검색 공간에서 10개의 대상 이미지를 무작위로 선택했습니다. 우리는 원래 Flickr-Faces-HQ (FFHQ) 데이터셋으로 훈련된 사전 훈련된 StyleGAN 모델을 사용했습니다. FFHQ 데이터셋은 GAN 벤치마크로 설계되었으며, 다양한 나이, 성별, 인종 및 얼굴 표정을 포함한 70,000개 이상의 1,024 × 1,024 크기의 인간 얼굴 이미지를 포함하고 있습니다.
We used FaceNet [29] to calculate the similarity between two images. FaceNet is a CNN model for facial recognition that converts facial images into embedded vectors. Using FaceNet, the embedding vectors of the generated and target images are obtained and the cosine similarity between the embedding vectors is calculated.
FaceNet을 사용하여 두 이미지 간의 유사성을 계산했습니다. FaceNet은 얼굴 인식을 위한 CNN 모델로, 얼굴 이미지를 임베딩 벡터로 변환합니다. FaceNet을 사용하여 생성된 이미지와 대상 이미지의 임베딩 벡터를 얻고, 이 임베딩 벡터 간의 코사인 유사성을 계산합니다.
4.2. 실험 결과
Figure 4 shows the moving average of the similarity for each 𝑑′.When 𝑑′ = 4, there was no significant diference between BanditBO and SimpleBO. For 𝑑′ = 8, BanditBO became closer to the target image more eficiently than SimpleBO compared to the case of𝑑′ = 4. Similarly, for 𝑑′ = 16, BanditBO became even closer to the target image more eficiently than SimpleBO. These results suggest that the proposed method approaches the target image more eficiently than the competing method when the search dimension is high.
그림 4는 각 𝑑′에 대한 유사성의 이동 평균을 보여줍니다. 𝑑′ = 4일 때, BanditBO와 SimpleBO 간의 차이는 중요하지 않았습니다. 𝑑′ = 8일 때, BanditBO는 SimpleBO에 비해 타겟 이미지에 더 효율적으로 가까워졌습니다. 𝑑′ = 16에서도 마찬가지로, BanditBO는 SimpleBO에 비해 타겟 이미지에 더욱 효율적으로 가까워졌습니다. 이러한 결과는 제안된 방법이 검색 차원이 높을 때 경쟁 방법보다 타겟 이미지에 더 효율적으로 접근한다는 것을 시사합니다.
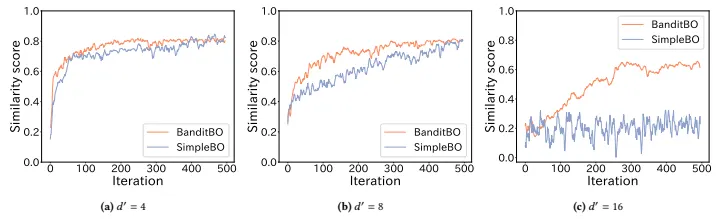
그림 4: d'에 대한 생성된 이미지와 대상 이미지 간의 유사성 추세(이동 평균의 평균에 대한 평균)
사용자 실험
5.1. 실험 설정
To verify whether the proposed method can eficiently generate preferred images in practical situations than the baseline methods, we conducted user experiments. Participants were asked to generate their preferred avatars for a scenario. We prepared six scenarios: lawyer, teacher, sports instructor, receptionist, library staf, and childcare worker. Each participant was asked to perform all the scenarios and the order of the scenarios was randomly shufled for each participant. There were three methods: BanditBO, SimpleBO,
and Random. The random method samples intermediate latent variables from the search space with a uniform distribution. The dimensionality of the subspace 𝑊 ′ was chosen from 𝑑′ ∈ {4, 16}.There were six conditions (three methods and two dimensions), and each of the six scenarios was randomly assigned to one of them without overlap for each participant. Fourteen participants (13 men and 1 woman, aged 18 to 27 years) participated in the study. The participants were told that they could only compare a maximum of fifty images in each scenario. Participants compared images on their PCs, not by swiping on their smartphones.
제안된 방법이 기본 방법들보다 실제 상황에서 선호하는 이미지를 효과적으로 생성할 수 있는지를 검증하기 위해 사용자 실험을 수행했습니다. 참가자들은 특정 시나리오에 대한 선호 아바타를 생성하도록 요청받았습니다. 우리는 변호사, 교사, 스포츠 강사, 접수원, 도서관 직원, 어린이 돌보미 등 여섯 가지 시나리오를 준비했습니다. 각 참가자는 모든 시나리오를 수행해야 했으며, 시나리오의 순서는 참가자마다 무작위로 섞였습니다. 세 가지 방법이 사용되었습니다: BanditBO, SimpleBO, 그리고 Random. 랜덤 방법은 검색 공간에서 중간 잠재 변수를 균일한 분포로 샘플링합니다. 서브스페이스 𝑊 ′의 차원은 𝑑′ ∈ {4, 16}에서 선택되었습니다. 여섯 가지 조건(세 가지 방법과 두 차원)이 있으며, 각 참가자에 대해 중복 없이 여섯 시나리오가 무작위로 하나의 조건에 할당되었습니다. 14명의 참가자(남성 13명, 여성 1명, 나이 18세에서 27세)가 이 연구에 참여했습니다. 참가자들은 각 시나리오에서 최대 50개의 이미지를 비교할 수 있다고 안내받았습니다. 참가자들은 스마트폰을 스와이프하는 것이 아니라, PC에서 이미지를 비교했습니다.
To let users assume the kind of image they want in advance, they were asked to imagine their preferences before starting each scenario. They were told that they did not necessarily have to generate images as per the preliminary questionnaire. They were also instructed to focus only on the faces for comparison. To evaluate whether the proposed method can eficiently generate preference images compared to the baseline methods, we prepared specific questions designed to gauge if the method eficiently arrived at the preferred images (Q1) and to assess the quality of the process of image generation (Q2, Q3) as well as the impression of the final generated image (Q4). The questions are as follows:
사용자가 미리 원하는 이미지에 대한 가정을 할 수 있도록, 각 시나리오를 시작하기 전에 자신의 선호를 상상해보도록 요청했습니다. 그들은 자료조사서에 따른 이미지 생성을 반드시 해야 하는 것은 아니라고 전달받았으며, 비교 시 얼굴에만 집중하라는 지시를 받았습니다. 제안된 방법이 기본 방법과 비교하여 선호 이미지를 효과적으로 생성할 수 있는지를 평가하기 위해, 우리는 방법이 선호 이미지에 효율적으로 도달했는지를 확인하는 질문(Q1)과 이미지 생성 과정의 품질을 평가하는 질문(Q2, Q3), 마지막으로 생성된 이미지에 대한 인상을 평가하는 질문(Q4)을 준비했습니다. 질문은 다음과 같습니다:
Q1. Were you able to reach the preferred image eficiently?
Q2. Did the images presented gradually change to the ones you preferred?
Q3. Did you find it easy to compare images each time?
Q4. Were you satisfied with the final image produced?
Q1. 원하는 이미지를 효율적으로 찾을 수 있었나요?
Q2. 제시된 이미지가 점차적으로 선호하는 이미지로 바뀌었나요?
Q3. 매번 이미지를 비교하는 것이 쉬웠나요?
Q4. 최종 이미지에 만족했나요?
We employed a seven-point Likert scale for these questionnaires (1: Strongly disagree, 7: Strongly agree), and the participants were asked through free description what they felt in the scenario. After going through all scenarios, participants were also asked to describe in free description what they felt throughout the experiment. Regarding eficiency, if BanditBO can generate preference images eficiently, then the number of image comparisons for BanditBO should be fewer than those of the baseline models. To verify this, we examined the distribution of the number of image comparisons required to generate the preference images. Also, regarding the dificulty of comparing images, if the comparison of images is challenging, it should take more time to select the images. For the time spent on selecting images at each iteration, we visualized the average selection time for each method and dimension.
우리는 이 질문지에 대해 7점 리커트 척도를 사용했습니다(1: 전혀 동의하지 않음, 7: 매우 동의함). 참가자들은 시나리오에서 느낀 바를 자유롭게 서술하도록 요청받았습니다. 모든 시나리오를 경험한 후, 참가자들은 실험 전반에 걸쳐 느낀 바를 자유롭게 서술하였습니다. 효율성과 관련하여, BanditBO가 선호 이미지를 효율적으로 생성할 수 있다면, BanditBO의 이미지 비교 수는 기준 모델들보다 적어야 합니다. 이를 검증하기 위해, 선호 이미지를 생성하는 데 필요한 이미지 비교 수의 분포를 조사했습니다. 또한 이미지 비교의 어려움과 관련하여, 이미지 비교가 어려운 경우 선택하는 데 시간이 더 걸려야 합니다. 각 반복에서 이미지 선택에 소요된 시간을 비교하기 위해 각 방법 및 차원에 대한 평균 선택 시간을 시각화하였습니다.
5.2. 결과
5.2.1. 효율성
Figure 5 shows the results of the question “Were you able to reach the preferred image eficiently?” It is observed that BanditBO outperformed the baselines with respect to the median by 2 points in 𝑑′ = 4 and 1 point in 𝑑′ = 8. Figure 6 illustrates the results of the distribution of the number of image comparisons needed to generate preferred images. The performance of BanditBO in the 𝑑′ = 4 case tends to have the lowest number of comparisons. The free description section in the questionnaire about BanditBO included the following responses: “It was a good generation, with fine-tuning, comparing significantly diferent images along the way, and then repeatedly coming back to the original route,” “There were various scenarios, such as a scenario where images were appropriately generated and no particular adjustments were made, or another with minor adjustments repeated over a long time, but the best scenario (BanditBO) was a mixture of the two, where I could fine-tune the image and then try one significant shift along the way and move to that scenario if necessary,” and “Compared to other scenarios, the changes in the image between iterations were smaller in most cases and seemed to be reached more eficiently.” From these, it was concluded that the proposed method can generate preferred images more eficiently by appropriately combining small and large changes. For SimpleBO with 𝑑′ = 4, although there was good feedback at some points, there were free descriptions such as “The images were dificult to select because most of them hardly changed, and when they did change, the changes were unrelated to the purpose of the image.” This indicates that SimpleBO dit not change what the user wanted to change.
그림 5는 "선호하는 이미지를 효율적으로 찾을 수 있었습니까?"라는 질문의 결과를 보여줍니다. BanditBO는 𝑑′ = 4일 때 중간값 기준으로 2점, 𝑑′ = 8일 때 1점 높아 baseline보다 성능이 우수한 것으로 관찰되었습니다. 그림 6은 선호하는 이미지를 생성하는 데 필요한 이미지 비교 수의 분포 결과를 나타냅니다. 𝑑′ = 4 경우에 BanditBO의 성능은 가장 적은 비교 수를 필요로 하는 경향이 있습니다. BanditBO에 대한 설문조사의 자유 기술 섹션에서는 다음과 같은 응답이 포함되어 있었습니다: “좋은 생성이었고, 신중하게 비교하며 여러 가지로 다른 이미지를 비교한 후 원래 경로로 되돌아오는 과정이 좋았다,” “이미지가 적절히 생성되어 특별한 조정이 필요하지 않은 경우와 약간의 조정이 반복된 경우 등 여러 시나리오가 있었지만, 최상의 시나리오(BanditBO)는 두 가지를 혼합한 것으로, 이미지를 세밀하게 조정한 다음, 그 과정에서 한 가지 중요한 변화를 시도하고 필요시 그 시나리오로 이동할 수 있었다,” 그리고 “대부분의 경우 반복 과정에서 이미지의 변화가 더 작았고, 더 효율적으로 도달하는 것처럼 보였다.” 이로부터, 제안된 방법이 작은 변화와 큰 변화를 적절히 결합하여 선호하는 이미지를 더 효율적으로 생성할 수 있다는 결론이 내려졌습니다. 반면, 𝑑′ = 4의 경우 SimpleBO에서는 몇 가지 긍정적인 피드백이 있었지만, “이미지가 거의 변하지 않아서 고르기 어려웠고, 변할 때도 이미지의 목적과 관련이 없는 변경이었다”라는 자유 기술이 있었습니다. 이는 SimpleBO가 사용자가 원하는 것을 변경하지 않았음을 나타냅니다.
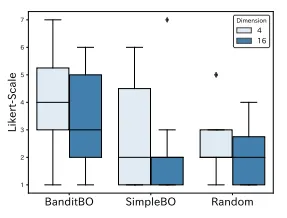
그림 5: "선호하는 이미지를 효율적으로 찾을 수 있었습니까?"라는 질문의 결과
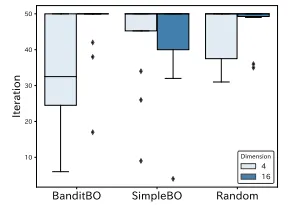
그림 6: 선호하는 이미지를 생성하는 데 필요한 이미지 비교 수의 분포 결과
5.2.2. 사용자 경험
Figure 7 shows the results of the question “Did the images presented gradually change to the ones you preferred?” This shows that the respondents evaluated the proposed method more favorably than the baseline methods and that there were many cases where the images changed to the preferred images. Figures 5 and 7 show that the performance of SimpleBO in the 𝑑′ = 4, case is not superior to that of BanditBO. The feedback from users included many comments such as “It was hard to choose images, as they changed very little most of the time, and when they did, the modifications were usually not related to the goal.” Consequently, SimpleBO had a negative user experience.
그림 7은 "제시된 이미지가 점차적으로 선호하는 이미지로 변화했습니까?"라는 질문에 대한 결과를 보여줍니다. 이는 응답자들이 제안된 방법을 기존 방법들보다 더 긍정적으로 평가했으며, 이미지가 선호하는 이미지로 변화한 경우가 많았음을 나타냅니다. 그림 5와 7은 SimpleBO의 성능이 𝑑′ = 4의 경우 BanditBO보다 우수하지 않음을 보여줍니다. 사용자 피드백에는 "이미지를 선택하기가 어려웠으며, 대부분의 경우 거의 변화가 없었고, 변화가 있을 때도 목표와 관련이 없는 수정이 대부분이었다"라는 많은 의견이 포함되어 있었습니다. 결과적으로 SimpleBO는 부정적인 사용자 경험을 가져왔습니다.
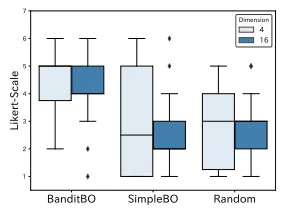
그림 7: “제시된 이미지가 점차적으로 선호하는 이미지로 변화했습니까?”라는 질문의 결과
Figure 8 shows the results of the question after each scenario, asking “Did you find it easy to compare images each time?” It can be seen that the comparison of images in the 𝑑′ = 4 cases of BanditBO and SimpleBO was dificult. The responses included many free descriptions, such as “The same images are generated continuously, making it dificult to select the best image.” It was found that users did not like comparisons of similar images. Figure 9 shows the distribution of average selection times for each method. BanditBO and SimpleBO have longer average selection times than Random. This may be attributed to the fact that similar images are dificult to compare, and therefore, the selection process takes longer.
그림 8은 각 시나리오 후 "매번 이미지를 비교하는 것이 쉬웠습니까?"라는 질문에 대한 결과를 보여줍니다. BanditBO와 SimpleBO의 𝑑′ = 4 경우에서 이미지 비교가 어려웠음을 알 수 있습니다. 응답에는 "같은 이미지가 계속 생성되어 최상의 이미지를 선택하기 어렵다"는 많은 자유로운 설명이 포함되어 있었습니다. 사용자들은 비슷한 이미지의 비교를 좋아하지 않는다는 것이 밝혀졌습니다. 그림 9는 각 방법에 대한 평균 선택 시간의 분포를 보여줍니다. BanditBO와 SimpleBO는 Random보다 평균 선택 시간이 더 길었습니다. 이는 유사한 이미지를 비교하는 것이 어려워 선택 과정이 더 오래 걸리기 때문일 수 있습니다.
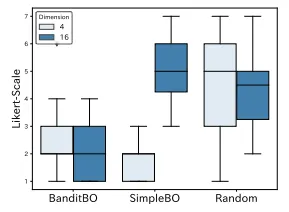
그림 8: “매번 이미지를 비교하는 것이 쉬웠습니까?”라는 질문에 대한 결과
5.2.3. 최종 결과에 대한 사용자 만족도
Figure 10 shows the results of the question asking “Were you satisfied with the final image produced?” after each scenario. This shows that users were more likely to be satisfied with the final image in the proposed method compared to the baseline in the 𝑑′ = 4 case. The variances in the distribution of results for the SimpleBO and Random questionnaires are greater than that of BanditBO. The results of the questionnaire for the Random method showed both a positive comment that the reason for the system stoppage was “because the avatar output was close to the image that was answered in the preliminary questionnaire,” and a negative comment in the free description that “the image did not change as expected.” The free description comments for SimpleBO also revealed both positive comments, such as, “There were some iterations that deviated from my expectations, but in the end I was able to create images that I was satisfied with.” and negative comments such as, “There were almost no changes in the images, and it was dificult to compare the results.” From these results, it is clear that SimpleBO and Random difer in the degree of satisfaction with the final image depending on users.
그림 10은 각 시나리오 후 "최종적으로 생성된 이미지에 만족하셨습니까?"라는 질문에 대한 결과를 보여줍니다. 이는 𝑑′ = 4 경우에서 제안된 방법이 기존 방법보다 최종 이미지에 대한 사용자 만족도가 높았음을 보여줍니다. SimpleBO와 Random 설문지 결과의 분포는 BanditBO보다 변동성이 큽니다. Random 방법에 대한 설문 결과에서는 "아바타 출력이 사전 설문지에 답한 이미지와 가까웠기 때문에 시스템이 중지되었다"는 긍정적인 의견과 "이미지가 예상대로 변하지 않았다"는 부정적인 의견이 자유 서술에서 모두 나타났습니다. SimpleBO의 자유 서술 의견에서도 "기대와는 다른 반복이 있었지만, 최종적으로 만족하는 이미지를 만들 수 있었다"는 긍정적인 의견과 "이미지에 거의 변화가 없었고 결과를 비교하기 어려웠다"는 부정적인 의견이 모두 나타났습니다. 이러한 결과로부터 SimpleBO와 Random이 최종 이미지에 대한 만족도에서 사용자에 따라 차이가 있음을 알 수 있습니다.
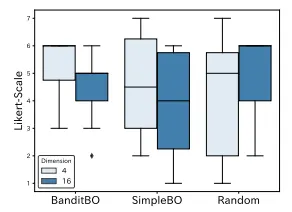
그림 10: “최종적으로 생성된 이미지에 만족하셨습니까?”라는 질문에 대한 결과
In summary, BanditBO generates preferred images eficiently, which gradually become closer to the preferred images, and the quality of the final generated image is also good. However, the drawback is that comparing images in each iteration is dificult and time-consuming.
요약하자면, BanditBO는 선호하는 이미지를 효율적으로 생성하여 점차 선호하는 이미지에 가까워지며 최종 생성된 이미지의 품질도 좋습니다. 그러나 각 반복에서 이미지를 비교하는 것이 어렵고 시간이 많이 걸리는 단점이 있습니다.
논의
6.1. 이미지 비교로 인한 선호도의 변화
The questionnaire responses included free descriptions such as “Gender of the presented image often changed during image generation depending on the occupation of the desired avatar. Also, images that were clearly diferent from what the user imagined were often generated during the process, but displaying an image that was completely diferent from the previous ones, sparked a sort of inspiration in changing my preferences of the avatar” and “I preferred to create male avatars, but several times women appeared along the way. The appearance of women changed my preferences a little, but on repeating the process of creation, my preference changed to men.” This suggests that human preferences change during image comparison. The proposed method responds to such changes in user preferences. The multi-armed bandit algorithm dynamically evaluates the contribution of each dimension to the current user preferences, allowing the generation of new images that correspond to changes in user preferences.
설문 응답에는 "원하는 아바타의 직업에 따라 생성 과정에서 제시된 이미지의 성별이 자주 바뀌었습니다. 또한, 사용자 상상과 명확히 다른 이미지가 생성되는 경우가 종종 있었는데, 이전과 완전히 다른 이미지를 표시하는 것이 아바타에 대한 선호도를 변화시키는 일종의 영감을 불러일으켰습니다."와 "남성 아바타를 선호했지만, 몇 번씩 여성 이미지가 나타났습니다. 여성 이미지의 등장은 제 선호도를 약간 바꾸었지만, 생성 과정을 반복하면서 다시 남성으로 선호도가 바뀌었습니다."와 같은 자유 서술이 포함되었습니다. 이는 이미지 비교 과정에서 인간의 선호도가 변화함을 시사합니다. 제안된 방법은 이러한 사용자 선호도의 변화에 반응합니다. 멀티암드 밴딧 알고리즘은 현재 사용자 선호도에 대한 각 차원의 기여도를 동적으로 평가하여 사용자 선호도 변화에 맞는 새로운 이미지를 생성할 수 있게 합니다.
A future approach for eficient response to temporal changes in preferences is to weight rewards by time using a multi-armed bandit algorithm: giving smaller weights to past rewards and larger weights to newer rewards. This method would make the proposed system more sensitive to recent preferences and allow an eficient response to subtle changes in user preferences.
선호도의 시간적 변화에 효율적으로 대응하기 위한 미래의 접근 방식은 멀티암드 밴딧 알고리즘을 사용하여 보상에 시간 가중치를 부여하는 것입니다. 과거 보상에는 작은 가중치를, 최신 보상에는 큰 가중치를 부여하는 방법입니다. 이 방법은 제안된 시스템이 최근 선호도에 더 민감하게 반응하고, 사용자 선호도의 미묘한 변화에 효율적으로 대응할 수 있게 할 것입니다.
6.1.1. 제안된 방법에서 사용자 탐색 범위의 확대 촉진
Previous research associates creative ideas with originality and usefulness [21]. Previous studies have proposed that in Bayesian optimization, exploration and exploitation are similar to the concepts of originality and usefulness, respectively, possibly bridging the connection with creativity [18]. Free descriptions about BanditBO included, “Two avatars that were quite similar were often presented. Sometimes they would change them a lot, but then they would return to the same picture and repeat fine-tuning,” and “It was doing a goodj ob of fine-tuning, repeatedly coming back to the original after comparing it to something significantly diferent along the way.” These observations indicate that Bayesian optimization can facilitate creativity. Furthermore, the final questionnaire included free descriptions such as, “There were various scenarios, such as a scenario where images were appropriately generated and no particular adjustments were made, or another with minor adjustments repeated over a long time, but the best scenario (BanditBO) was a mixture of the two, where I could fine-tune the image and then try one significant shift along the way and move to that scenario if necessary.” This suggests that the balance between exploration and exploitation of the proposed method is similar to that between originality and usefulness in creative idea generation. In particular, the BanditBO approach enables the retention of originality while pursuing usefulness.
이전 연구는 창의적인 아이디어를 독창성과 유용성과 연관시켰습니다 [21]. 이전 연구들은 베이지안 최적화에서 탐색과 활용이 각각 독창성과 유용성과 유사하다고 제안하며, 이는 창의성과의 연결을 가능하게 합니다 [18]. BanditBO에 대한 자유 서술에는 "매우 유사한 두 아바타가 자주 제시되었습니다. 때로는 크게 바꾸기도 했지만, 같은 그림으로 돌아와 세밀한 조정을 반복했습니다."와 "세밀한 조정을 잘 해내면서 가는 길에 상당히 다른 것과 비교한 후 원래대로 돌아왔습니다."와 같은 내용이 포함되었습니다. 이러한 관찰은 베이지안 최적화가 창의성을 촉진할 수 있음을 나타냅니다. 또한, 최종 설문에는 "적절하게 이미지가 생성되고 특별한 조정이 없는 시나리오나, 오랜 시간 동안 소소한 조정이 반복된 시나리오 등이 있었지만, 최고의 시나리오(BanditBO)는 두 가지가 혼합되어 있었고, 이미지를 세밀하게 조정한 후 한 번 큰 변화를 시도하고 필요할 때 그 시나리오로 이동할 수 있었습니다."라는 자유 서술이 포함되었습니다. 이는 제안된 방법의 탐색과 활용 사이의 균형이 창의적 아이디어 생성에서의 독창성과 유용성 사이의 균형과 유사함을 시사합니다. 특히, BanditBO 접근 방식은 유용성을 추구하면서도 독창성을 유지할 수 있게 합니다.
6.2. 생성된 이미지의 다양성과 사용자 만족도 사이의 관계
The general feedback from the participants included the following text: “Scenarios with poor eficiency had images generated that were almost unrelated to each other in sequence, and I felt it did not respond to my comparisons. For scenarios where the eficiency was good, images began to be changed little by little from a small number of images, and I felt that the selections reflected my choices, but the output after that was almost determined by the first selected image, and I felt that it settled into the locally optimal image.” These comments indicate that the images generated by the proposed method lack diversity compared to those generated by Random. We also believe that the diversity of images difer based on the size of subspace, rather than diferences between methods. We assessed the size of the subspace and the expressive power of the GAN by generating multiple images from random samples 𝑤′for each 𝑑′to confirm the variety of the generated images in diferent dimensions 𝑑′.
참가자들로부터의 일반적인 피드백에는 다음과 같은 내용이 포함되었습니다: "효율성이 낮은 시나리오에서는 연속적으로 거의 관련이 없는 이미지가 생성되어, 내 비교에 반응하지 않는다고 느꼈습니다. 효율성이 좋은 시나리오에서는 소수의 이미지에서 조금씩 변경이 시작되었고, 선택이 내 선택을 반영한다고 느꼈지만, 그 후의 출력은 거의 처음 선택한 이미지에 의해 결정되어 국지적인 최적의 이미지에 정착한 것 같았습니다." 이러한 의견은 제안된 방법으로 생성된 이미지가 Random으로 생성된 이미지에 비해 다양성이 부족함을 나타냅니다. 또한, 이미지의 다양성은 방법 간의 차이보다는 부분 공간의 크기에 따라 달라진다고 생각합니다. 우리는 각 𝑑′에 대해 무작위 샘플 𝑤′로부터 여러 이미지를 생성하여 다양한 차원 𝑑′에서 생성된 이미지의 다양성을 확인함으로써 부분 공간의 크기와 GAN의 표현력을 평가했습니다.

그림 11: 차원에 따른 이미지 생성 결과
The results are shown in Figure 11. A wide variety of images were generated with a latent space dimension of 8 and 16. However, with a latent space dimension of 4, similar images were generated but lacked diversity. Reducing the latent space of StyleGAN using Principal Component Analysis (PCA) confirmed qualitatively that the expressiveness of StyleGAN's image generation diminished. Additionally, free descriptions related to the Random method with a latent space dimension of 4 included responses such as, "Images seen before often reappeared." These results indicate that the latent space with a dimension of 4 lacked diversity in the generated images compared to the space with a dimension of 16.
결과는 그림 11에 나타나 있습니다. 𝑑′ = 8 및 16에서 다양한 이미지가 생성되었습니다. 그러나 𝑑′ = 4에서는 유사한 이미지가 생성되었으나 다양성이 부족했습니다. PCA를 사용하여 StyleGAN의 잠재 공간을 축소한 결과, StyleGAN의 이미지 생성에서 표현력이 감소한 것을 질적으로 확인할 수 있었습니다. 또한, 𝑑′ = 4에서 Random에 대한 자유 서술에는 "이전에 본 이미지가 자주 다시 나타났다"는 등의 응답이 포함되었습니다. 이러한 결과는 𝑑′ = 4의 잠재 공간이 𝑑′ = 16의 잠재 공간에 비해 생성된 이미지의 다양성이 부족했음을 시사합니다.
However, responses for both dimensions included comments such as, “I was able to generate an avatar that was close to the image I answered in the preliminary questionnaire,” and “I was able to generate an image that I was satisfied with, even though it was diferent from my initial image.” This suggests that although diferences in dimensionality afect the diversity and expressiveness of the generated images, they may not directly afect the ability to generate images that satisfy the user.
그러나 두 차원 모두에 대한 응답에는 "사전 설문지에 답한 이미지에 가까운 아바타를 생성할 수 있었다" 또는 "초기 이미지와는 다르지만 만족스러운 이미지를 생성할 수 있었다"는 댓글이 포함되었습니다. 이는 차원의 차이가 생성된 이미지의 다양성과 표현력에 영향을 미치지만, 사용자 만족도를 충족하는 이미지를 생성하는 능력에는 직접적인 영향을 미치지 않을 수 있음을 시사합니다.
6.3. 시나리오 설정의 영향
그림 12는 각 시나리오에 대한 사후 설문조사 결과를 보여줍니다. 결과는 다음과 같습니다: (a) 사용자는 도서관 직원보다 교사의 선호 이미지를 더 효율적으로 달성했다; (b) 교사 시나리오에서는 변호사 시나리오에 비해 이미지가 선호도에 점차적으로 더 많이 맞춰졌다; (c) 사용자는 체육 강사와 교사 시나리오보다 어린이집 보육 교사 시나리오에서 각 반복에서 이미지를 비교하기가 더 쉬웠다고 느꼈다; (d) 최종 생성된 이미지에 대한 만족도가 교사 시나리오에서 스포츠 강사 시나리오보다 더 높았다. 이러한 결과는 제시된 시나리오가 설문조사에 영향을 미쳤을 수 있음을 나타냅니다.
사전 설문조사를 시나리오별로 살펴보았을 때, 변호사 시나리오의 경우 75% 이상의 참가자가 "40대"라는 키워드를 사용한 반면, 교사 시나리오에서는 "20대"에서 "60대"까지의 다양한 연령대가 언급되었습니다. 또한, 접수 담당자 및 어린이집 보육 교사에 대한 사전 조사에서는 응답자의 92% 이상이 "여성"이라고 응답한 반면, 교사와 체육 강사의 경우 "남성"과 "여성"이 모두 포함되었습니다. 이러한 관찰을 통해 중요한 통찰을 얻을 수 있습니다. 첫째, 교사 시나리오의 사전 설문조사가 다양한 연령대와 성별의 응답을 포함했기 때문에 교사의 이미지가 더 다양하고 유연하게 생성될 수 있었고, 이로 인해 이미지 생성이 더 효율적이고 사용자 만족도가 높아졌을 수 있습니다. 반대로, 변호사, 어린이집 보육 교사 및 접수 담당자 시나리오에서는 키워드가 일관되게 설정되었고 시나리오에 따라 이미지를 생성하라는 지시가 있었기 때문에 결과에 강한 사용자 선입견이 영향을 미쳤을 가능성이 높습니다.
그림 13은 시나리오별 참가자들의 평균 선택 시간을 보여줍니다. 어린이집 보육 교사 시나리오의 평균 선택 시간은 교사 시나리오보다 짧았습니다. 어린이집 보육 교사에 대한 고정관념이 교사 시나리오에서 다양한 선입견을 가진 사용자들보다 이미지를 비교하기 쉽게 했을 수 있습니다. 이러한 요소들이 이미지 정확도와 사용자 만족도에 미치는 영향을 탐색하는 것은 향후 연구에서 자세히 분석할 필요가 있습니다.
설계 시사점
7.1. 사용자 지향 시스템
이 섹션에서는 사용자 선호 이미지를 생성하기 위한 시스템의 사용성 개선과 관련된 몇 가지 중요한 측면을 논의합니다. 설문 응답에는 시스템에서 조정되었으면 하는 내용에 대한 자유 서술이 포함되었습니다. 예를 들어, "두 이미지 중 하나를 선택하도록 강제되는 것보다 선택하지 않는 옵션이 있었으면 좋겠다. 원하지 않는 두 이미지 중 하나를 선택해야 했기 때문에 완전히 다른 방향으로 진행되었다," "선호 이미지와 크게 다른 이미지는 생략하는 것이 더 효율적일 수 있다," 그리고 "안경 부분을 변경하고 싶었지만, 안경 외의 부분이 계속 변경되었고 원하는 이미지를 얻기 어려웠다"라는 의견이 있었습니다. 이러한 사용자 응답은 시스템에서 자율성을 선호한다는 것을 나타냅니다. 이전 연구에서는 베이지안 최적화를 통해 인간 디자이너가 완벽한 제어를 하는 개념을 제안했습니다 [18]. 그러나 이 개념에 대한 실험은 아직 수행되지 않았으므로 사용자가 사용자 지향 시스템을 필요로 하는지 여부는 불확실합니다. 반면, 우리의 실험 결과는 사용자 지향 설계의 필요성을 드러냅니다. 따라서 사용자 지향 요소를 시스템에 통합하는 시범 실험을 제안합니다. 이 연구는 스마트폰 조작을 전제로 했으며, 이는 낮은 조작성으로 인해 여러 슬라이더 조정에 제한을 두었습니다. 사용자 지향 설계를 시스템 디자인에서 고려할 때 이러한 제약을 염두에 두어야 합니다.
7.2. 비교 이미지 검토
설문 응답에는 "선택하지 않은 이미지가 다음 비교 대상이 되었을 때, 선호 이미지와의 비교가 멀어지는 느낌이 들어 불쾌했다," "이전 비교에서 선택한 이미지가 다음 비교로 이어지는 것이 더 나은 비교 수단일 것이라고 생각했다"는 등의 자유 서술이 포함되었습니다. 이러한 결과는 사용자가 시스템이 이전 비교에서 선택한 이미지를 새로 생성된 이미지와 비교하기를 원했다는 것을 보여줍니다. 그러나 이 연구는 스마트폰 조작을 전제로 했으며, 화면이 작기 때문에 하나의 이미지만을 표시하는 사용자 인터페이스를 채택했습니다. 이러한 경우, 이전에 생성된 이미지와 현재 이미지를 비교하는 것이 자연스럽다고 생각됩니다. 스마트폰에서 쌍별 비교를 위한 최적의 사용자 인터페이스를 고려할 필요가 있습니다.
7.3. 이미지 변화 시각화
설문 응답에는 "두 이미지의 미세 조정 차이를 이해하기 어려운 경우가 많다. 기능 기준으로 제공하는 경우 두 이미지의 차이에 대한 작은 설명이 있으면 좋겠다"는 자유 서술이 포함되었습니다. 이는 이전 이미지와 비교하여 새로 생성된 이미지의 변경된 부분을 시각화할 필요가 있음을 시사합니다. 이를 해결하는 한 가지 방법은 두 이미지 간의 픽셀 또는 특징 수준의 차이를 계산하고, 그 차이를 히트맵 또는 마스크로 표시하는 것입니다. 이를 통해 변경된 부분을 한눈에 확인할 수 있습니다. 생성된 이미지에 기존의 특징 추출 알고리즘을 적용하고 결과를 비교하는 것도 유용할 것입니다. 이러한 특징 기반 접근 방식은 더 높은 의미 수준에서 차이를 캡처하는 데 도움이 될 것입니다.
7.4 탐색과 활용 사이의 균형 표시
설문 응답에는 "내 선택이 이미지의 대략적인 범위를 좁히고 있는지, 아니면 상세한 특징을 선택하고 있는지에 대한 정보를 제공받는다면 선택에 대한 불안을 줄일 수 있을 것 같다"는 자유 서술이 포함되었습니다. 사용자 불안을 완화하기 위해, 베이지안 최적화의 탐색과 활용 간의 현재 균형을 사용자에게 표시하는 것이 유용하다고 생각했습니다. 7.1절에서 설명한 바와 같이, 사용자가 베이지안 최적화의 탐색과 활용 간의 균형을 조정할 수 있도록 하는 것은 향후의 전망입니다. 그러나 디자이너는 여전히 이러한 조정을 용이하게 할 방법과 인터페이스 복잡성 문제를 해결해야 하며, 사용자가 탐색과 활용의 감각을 습득하는 것을 돕는 것이 여전히 필요합니다.
결론
우리는 제안된 방법이 쌍별 비교 결과만으로도 선호 이미지를 경쟁 방법보다 더 효율적으로 생성할 수 있음을 입증했습니다. StyleGAN의 잠재 공간을 차원 축소를 위해 PCA를 적용하고 사용자에게 관심이 있는 차원에 집중함으로써, 선호 이미지 생성이 기존 방법보다 더 효율적임을 발견했습니다. 또한, 이 논문은 스마트폰 조작을 사용한 새로운 선호 이미지 생성 접근 방식을 제안했습니다.
향후 연구에는 더 많은 탐색 차원에서도 적은 수의 반복으로 선호 이미지를 생성할 수 있는 효율적인 검색 방법 개발이 포함될 것입니다. 특히, 이미지 제시부터 스와이프까지 경과 시간과 같은 추가 정보를 사용하여 선호 이미지를 생성하는 데 필요한 반복 횟수를 줄이는 것을 목표로 합니다. 또한 시스템을 더 사용자 친화적으로 만드는 것도 향후 연구의 일환으로 포함될 것입니다.