최근 운영 중인 카카오 챗봇에서 API 요청을 보낸 후 응답 시간이 5초 이상 지연되는 문제가 발생했다. 이로 인해 NGINX 로그에는 HTTP 499 오류가 기록되었고, 사용자 경험에도 악영향을 미쳤다. 문제를 해결하는 과정에서 겪은 시행착오와 최적화 방법을 공유해본다.
문제 상황
기존에는 학과 내에서 직접 서버를 운영하고 있었지만, 유지보수와 안정성을 고려해 GCP e2-micro 인스턴스로 마이그레이션을 진행했다. 사양이 빵빵했던 온프레미스 환경에서 클라우드의 가벼운 인스턴스로 옮기면서 성능 차이가 어느 정도 발생할 거라고 예상하긴 했지만, 예상보다 훨씬 심각한 문제가 터졌다.
서버를 이전한 뒤 API 응답 속도가 이상할 정도로 느려진 것이다. 평소에 별문제가 없다가도 유휴(idle) 상태였다가 처음 요청을 받을 때 30초 이상 지연되는 현상이 반복됐다. 심지어 NGINX 로그를 살펴보니 HTTP 499 오류가 자주 발생하고 있었다. 사용자들은 버튼을 눌러도 응답이 오지 않아 답답해했고, 나 역시 원인을 쉽게 찾을 수 없었다.
아래는 문제를 나타내는 NGINX 로그이다.
219.xxx.xxx.xx - - [03/Jan/2025:11:44:56 +0000] "POST /api/spring/dish HTTP/1.1" 200 647 "-" "AHC/2.1" "-"
219.xxx.xxx.xx - - [03/Jan/2025:12:08:37 +0000] "POST /api/spring/cafeteria HTTP/1.1" 499 0 "-" "AHC/2.1" "-"
219.xxx.xxx.xx - - [03/Jan/2025:12:09:08 +0000] "POST /api/spring/department-notice HTTP/1.1" 499 0 "-" "AHC/2.1
Bash
복사
서버 환경

1.
GCP e2-micro Instance 사양
항목 | 사양 |
머신 타입 | e2-micro |
OS | Ubuntu 20.04.1 |
리전 | us-west1-a |
CPU | vCPU 2개 |
RAM | 1GB |
SSD | 30GB |
2.
Supabase DB 사양
항목 | 사양 |
플랜 | Free |
CPU | 공유 CPU |
RAM | 500MB |
스토리지 | 기본 1GB |
대역폭 제한 | 5GB |
API 요청 | 무제한 |
원인 분석
우선 API 서버에서 어떤 일이 벌어지는지 살펴보기 위해 Spring과 NestJS 두 API 서버 별 응답 시간 실험을 진행했다.
Spring
Postman 응답 결과 (Spring)
NestJS
Postman 응답 결과 (NestJS)
두 서버 모두 공통적으로 첫 요청만 유독 느리다는 사실을 확인했다. 즉, 특정 프레임워크의 문제라기보다는 서버 자체가 첫 요청을 받을 때 뭔가 준비하느라 시간이 오래 걸린다는 의미다.
또, 첫 요청 외에도 이후 요청들도 평균 응답시간이 1,000ms 이상으로 다소 길게 나타났다. 특히, 스프링 기반 API의 경우에는 평균 2~4초까지 소요되는 경우도 있었고, NestJS 기반 API도 기대했던 성능보다 다소 느렸다.
해결 과정
 데이터베이스 인덱스 문제?
데이터베이스 인덱스 문제?
첫 번째로 의심한 것은 데이터베이스 인덱스 미적용으로 인한 풀스캔 문제였다.
일부 API에서 쿼리 실행 시간이 800ms 이상 걸리는 경우가 있어, 혹시 특정 테이블에서 인덱스가 빠져있는 것은 아닌지 점검했다.
우선, 실행 계획을 확인해보았다.
EXPLAIN ANALYZE SELECT * FROM kakao-user WHERE id = 'test1234';
TypeScript
복사
만약 인덱스가 없다면, 이 쿼리는 user 테이블 전체를 스캔하면서 조건에 맞는 데이터를 찾게 된다. 하지만 실행 결과, 주요 조회 쿼리에는 이미 적절한 인덱스가 설정되어 있었고, 쿼리 실행 시간이 비정상적으로 길지는 않았다. 즉, 데이터베이스의 인덱스 문제는 이번 성능 저하의 주된 원인이 아니었다.
네트워크 레이턴시 문제?
그렇다면, 다른 원인을 찾아봐야 했다. 다음으로 의심한 것은 네트워크 레이턴시였다.
GCP 환경으로 이전하면서 서버의 물리적인 위치가 us-west1-a로 변경되었기에 충분히 의심해볼만했다.
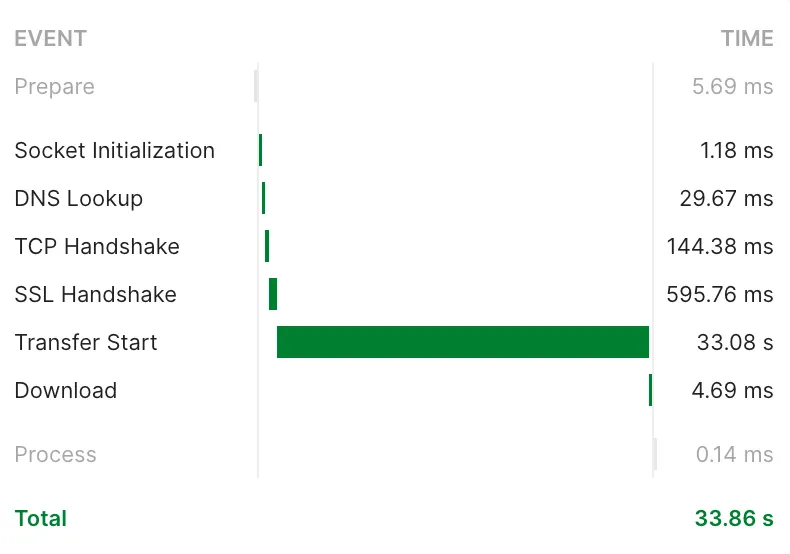
Postman의 응답 시간을 보면, 초기 연결 과정(TCP Handshake, SSL Handshake)은 약 0.74초가 걸렸지만, 실제 데이터 전송(Transfer Start)에 33초가 걸렸다.
따라서, 네트워크 레이턴시 문제라기보다는 애플리케이션 내부의 처리 속도가 원인일 가능성이 크다고 판단했다.
애플리케이션 내부의 처리 속도 문제?
네트워크 문제가 아니라면, 남은 가능성은 애플리케이션 내부의 처리 속도 문제였다.
GCP 프리 티어 e2-micro 인스턴스를 사용 중이었기 때문에, 낮은 CPU 성능과 제한된 메모리로 인해 성능 저하가 발생할 가능성이 컸다.
애플리케이션이 Docker 컨테이너에서 실행 중이었기 때문에, 리소스 사용량을 확인해보았다.
docker stats
Shell
복사

그런데 예상과는 다르게 CPU 사용량과 메모리 사용량은 심각한 수준이 아니었다.
하지만, 한 가지 거슬렸던 것은 BLOCK I/O였다.
Spring과 NestJS 컨테이너 모두 높은 BLOCK I/O 사용량을 보이고 있었다.
이 부분을 확인해보고 싶어 디스크 입출력에 대한 통계정보를 측정해주는 iostat을 이용해 보기로 했다.
디스크 I/O 분석
다음 명령어를 실행하여 디스크 I/O 상태를 실시간으로 확인했다.
iostat -dx 1
Shell
복사

출력 결과를 살펴보니 %util 값이 90% 이상으로, 디스크 사용률이 매우 높았다.
또한, %iowait 값도 마찬가지로 90% 이상으로 CPU가 I/O 대기로 인해 작업을 처리하지 못하는 상황이다.
즉, CPU는 놀고 있는데 디스크가 병목이 되어 전체 성능이 저하되는 상황이었다.
그래서 관련된 내용을 구글링하다가 아래 블로그들 글에서 답을 얻었다. (감사합니다..)





운영체제는 메모리가 부족할 시 디스크 스왑 공간을 활용하는데, vm.swappiness 값에 따라 스왑을 얼마나 적극적으로 사용할지 결정한다.
•
0: 가급적 스왑을 사용하지 않음 (오히려 메모리가 거의 꽉 찼을 때만 사용)
•
1~100: 값이 높을수록 스왑을 더 적극적으로 사용 (기본값은 보통 60)
문제의 원인은 GCP 인스턴스에서 메모리가 부족하지 않았음에도 불구하고, vm.swappiness 값이 높게 설정되어 있어서 디스크 스왑이 과도하게 발생했고, 그로 인해 디스크 I/O 병목이 일어났던 것이었다.
해결 방법
디스크 스왑 최소화
•
아래 명령어로 현재 vm.swappiness 값을 확인한다.
cat /proc/sys/vm/swappiness
Shell
복사
•
값이 60처럼 높다면, 이를 1로 조정한다. 또, 영구 적용을 위해 /etc/sysctl.conf 파일에 추가
echo "vm.swappiness=1" | sudo tee -a /etc/sysctl.conf
Shell
복사
•
적용 후 다시 sysctl -p를 실행하여 반영한다.
sudo sysctl -p
Shell
복사
성능 개선 결과
디스크 스왑 설정을 조정한 후 API 응답 시간이 크게 개선되었다.
아래 사진은 변경 후의 성능 측정 결과다.
대부분의 API 응답 요청이 기존 2~4초에서 1초 이내로 크게 개선되었다.


마치며
처음에는 단순히 서버 사양 차이로 인한 성능 저하라고 생각했지만, 실제로는 운영체제 설정의 문제였다.
이는 클라우드 환경으로 마이그레이션할 때 단순히 애플리케이션 코드만 옮기는 것이 아니라, 운영체제 레벨의 설정까지 고려해야 함을 보여준다.
특히 저사양 환경에서는 메모리와 디스크 I/O 간의 균형이 매우 중요하다는 것을 깨달았다. 무작정 높은 사양의 인스턴스를 사용하는 것보다, 현재 인스턴스를 최적화하는 것이 비용 효율적인 해결책이 될 수 있다.
이 경험이 비슷한 문제를 겪고 있는 개발자들에게 도움이 되길 바란다.



